I've been running some of the biggest open-weight LLMs for free on Nvidia's cloud
…There's no realistic way for me to run MiniMax M2.7 on the ThinkStation PGX. The full model needs serious hardware, and using the 3-bit quantization to run it on…
…There's no realistic way for me to run MiniMax M2.7 on the ThinkStation PGX. The full model needs serious hardware, and using the 3-bit quantization to run it on…
Ayush Pande Apr 15, 2026, 2:30 PM EDT Ayush Pande is a PC hardware and gaming writer. When he's not working on a new article, you can find him with…
Ayush Pande Apr 11, 2026, 3:30 PM EDT Ayush Pande is a PC hardware and gaming writer. When he's not working on a new article, you can find him with…
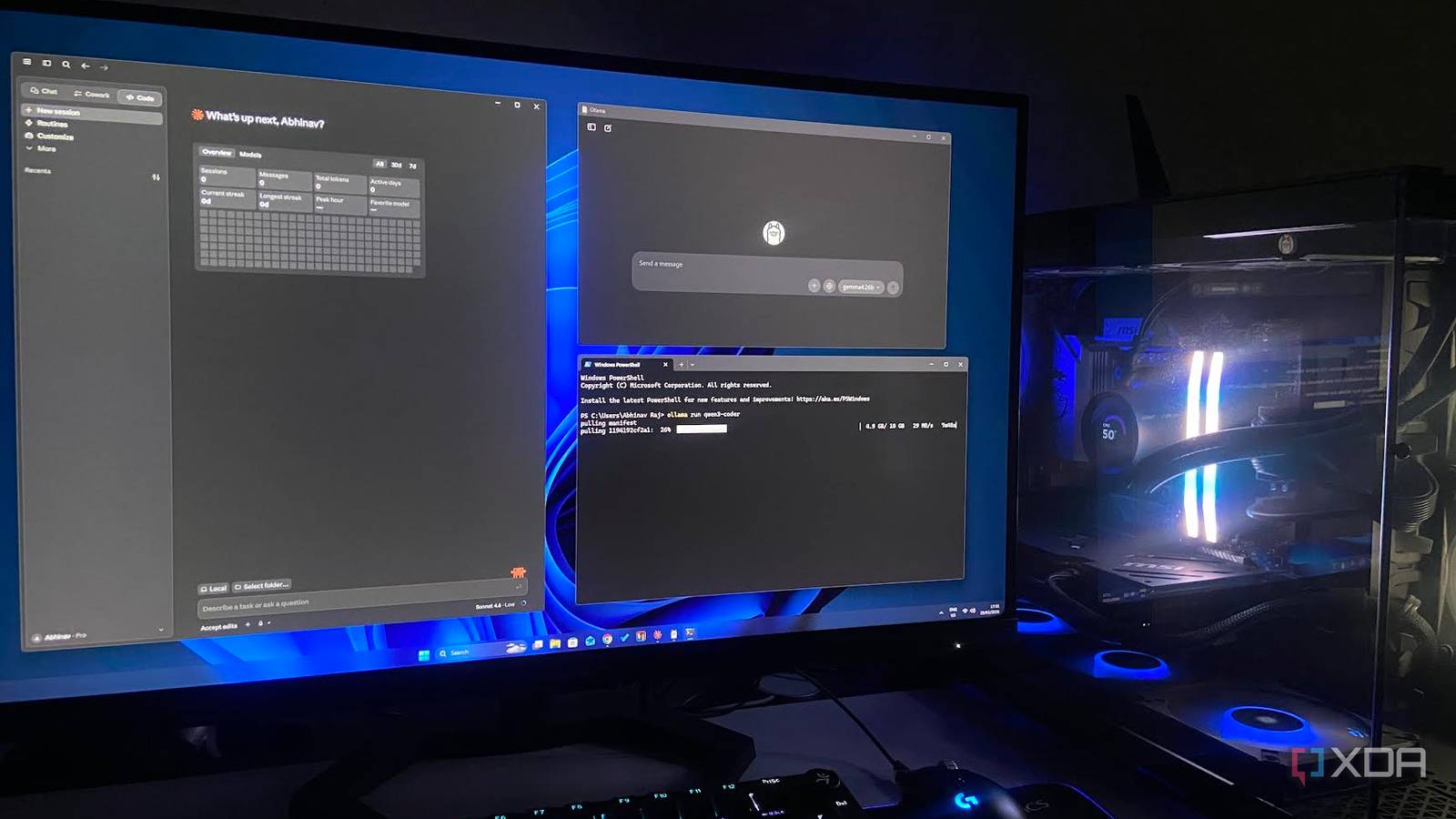
…The two models I keep coming back to are Qwen 3.5 9B and Gemma 4 E4B, both running fine on my 8GB VRAM, so hardware isn't really the bottleneck for…
…It simplifies the process of pulling and serving open-weight models on consumer hardware. Think of it as the 'Docker for LLMs,' giving you a clean interface to run powerful models without…
…It's been sitting in my rotation for a few weeks now because I could actually run it on my hardware. And what I found was less about whether it could keep…
Ayush Pande Mar 28, 2026, 3:31 PM EDT Ayush Pande is a PC hardware and gaming writer. When he's not working on a new article, you can find him with…
To show you the most relevant results, we’ve omitted some entries very similar to those already shown. Repeat the search with the omitted results included.