I ditched Claude Code for Perplexity, then realized I needed both all along
…See at Perplexity Multi-model workflows are the way to go One model isn't enough for every task I've come to realize that one model isn't enough for every…
…See at Perplexity Multi-model workflows are the way to go One model isn't enough for every task I've come to realize that one model isn't enough for every…
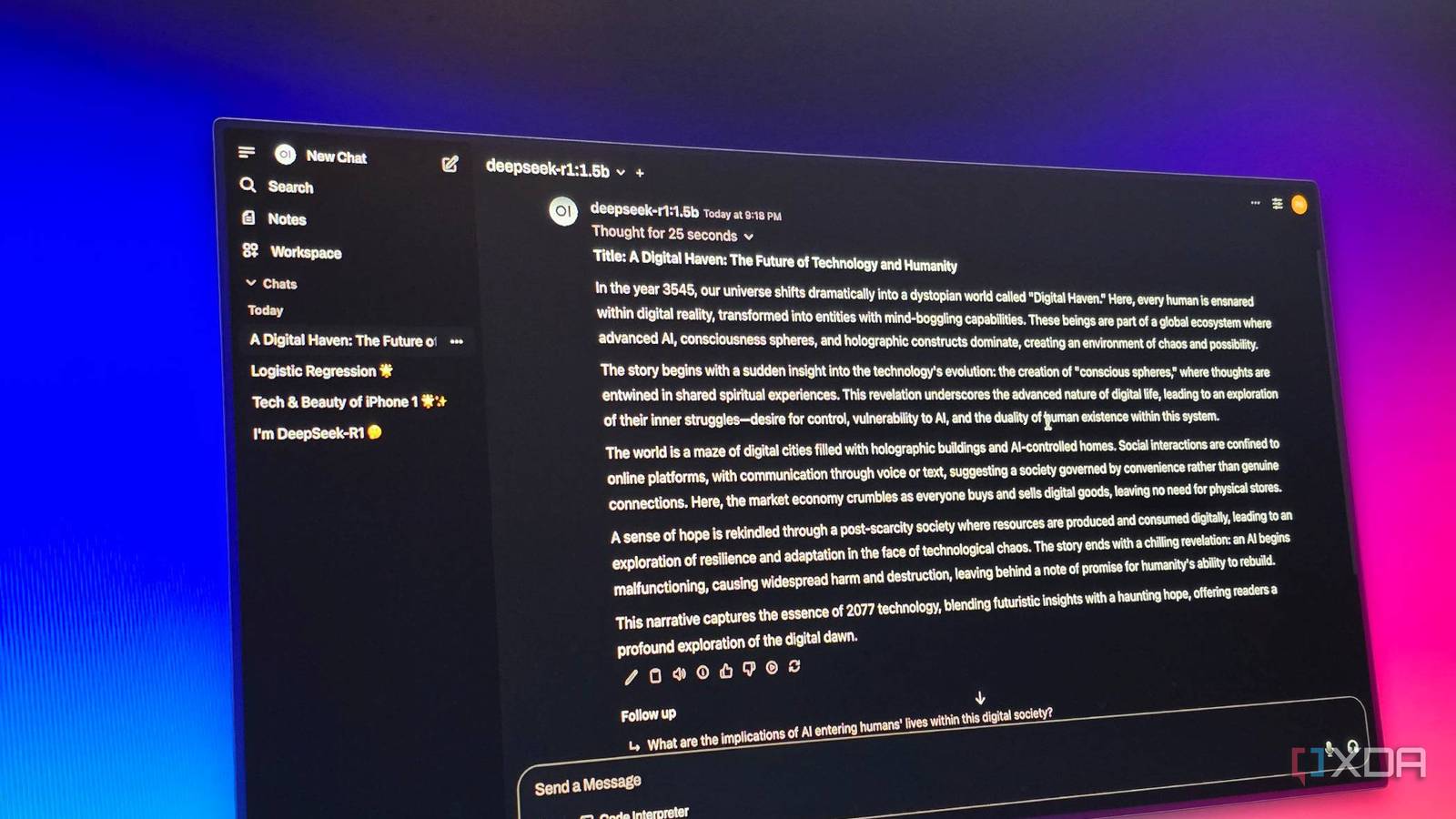
…But after testing all sorts of models on my workstation nodes and pairing them with the self-hosted FOSS utilities in my home lab, I’ve learned that local models can become…
…I would focus on keeping just a few reliable models. Most daily tasks don’t need ten different models. One fast model for quick tasks, one stronger model for deeper thinking, and…
…Upgrading my local model with a simple tool Adding Brave Search MCP to my local LLM didn’t completely transform it into a perfect system, but it solved one of its biggest…
…You can upgrade from 14B to 32B models, unlocking another level of reasoning quality. With the capability to run quantized 70B models, the RTX 3090 allows you to get the true local…
…tell either model the VM was disposable, but Qwen, to my surprise, took this as encouragement. It started with the standard "make my PC fast" routine: disable unattended-upgrades, replace swap with…
…Equipped with an Intel Core Ultra 9 processor, 32GB RAM, and an Nvidia GeForce RTX 5070, I can run heavy 14B models with zero lag. I even run a few 20B models…
…but hasn't upgraded you yet simply because you haven't asked. I got my ISP to replace my Wi-Fi 5 router with a Wi-Fi 6 model, so the switch…
…slow waits, but the four physical cores and upgradable RAM do provide some wiggle room for heavier tasks, such as running local models. I found anything under 10B to be entirely possible…
…Related Modern GPUs are incredible, but they broke the idea of sensible upgrades A GPU upgrade doesn't feel like one anymore, at least not the way we remember Neural Texture Compression…