Speculative decoding made my local LLM actually usable
…Related Here's how I get the most out of my self-hosted LLM, especially when limited by VRAM Don't have an RTX 5090? No problem! Running a local LLM is…
…Related Here's how I get the most out of my self-hosted LLM, especially when limited by VRAM Don't have an RTX 5090? No problem! Running a local LLM is…
…Recently, I came across a tool called Fabric, which is meant to simplify repetitive LLM work. Combining that with my local LLM and Obsidian setup, I think I may have stumbled on…
…But local LLMs are not search engines. They don't index the web to guess what you mean; they predict the next token based strictly on the context you provide. When I…
…Related Local LLMs didn't save me time until I gave them a job they're actually good at I'd been sleeping on local LLMs all this time OMNI now lives…
…A local LLM is worth the hassle A local LLM It is not as good as using something like Claude through the cloud, but it is still far better than having nothing…
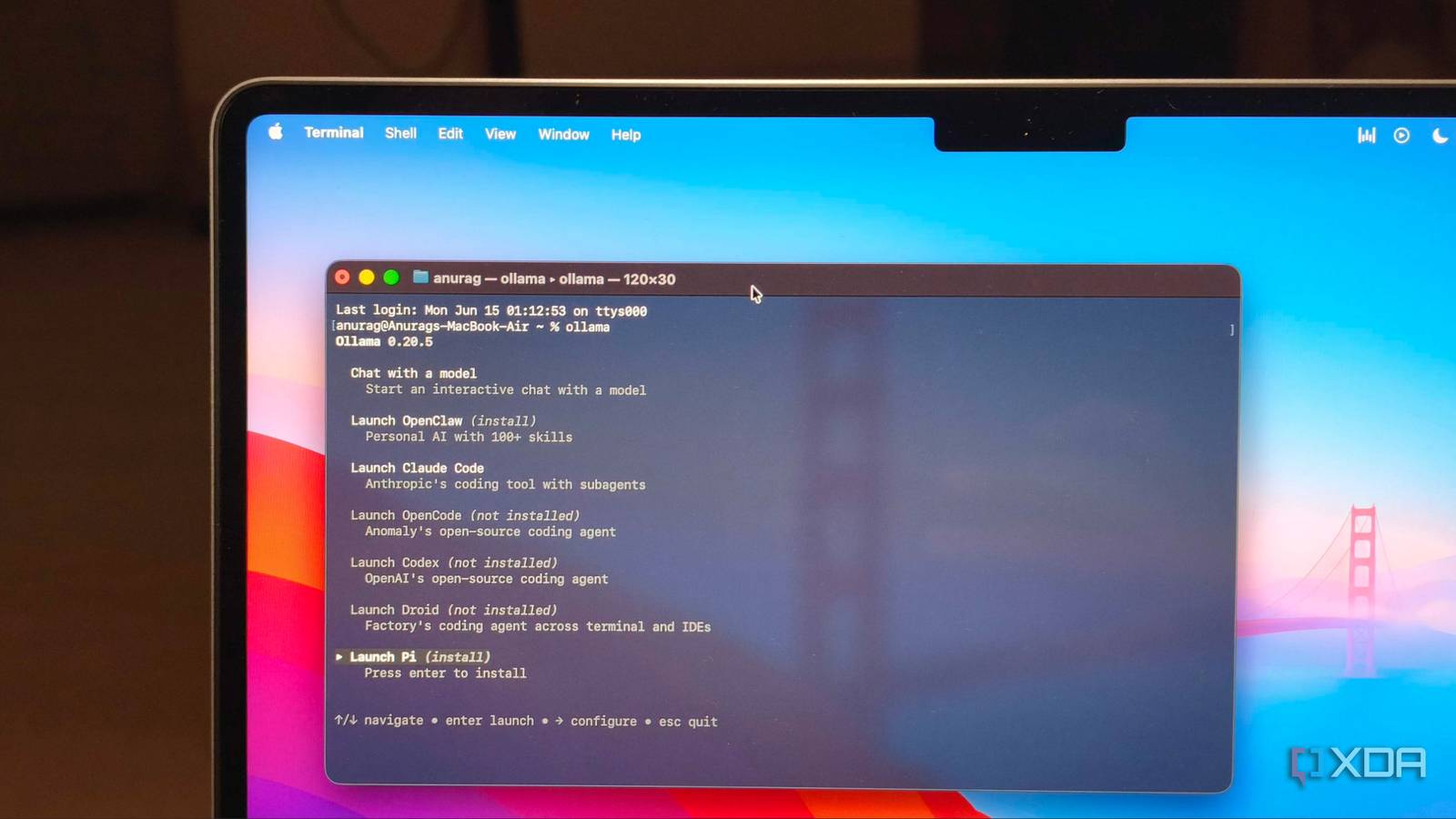
…Sign in to your XDA account I was impressed with how quickly it was to get a local LLM up and running with Ollama. It was as simple as downloading the installer…
…Giving the model local memory via RAG I built a private memory for my local LLM A local LLM is great, but it has a massive blind spot: it doesn’t know…
…local LLMs was with LM Studio . It seemed to be the best option for starting out, with one program to download that would serve as both a user interface and an LLM…
…Ollama Ollama is a platform to download and run various open-source large language models (LLM) on your local computer. See at Ollama Related Google's Gemma 4 finally made me care…
…If your local LLM has become backend infrastructure for your home lab, vLLM and SGLang are closer to the right shape of what you need. vMLX gives Macs a more serious local…