




Paper page - Qwen-Image-Flash: Beyond Objective Design
["qwen3"]
Tracked topic
Qwen3 is an AI model family developed by Alibaba, released as a set of large language models for natural-language tasks.
["qwen3"]
…Model Backend TTFT (ms) TPS VRAM peak (GB) Llama 3.2 3B Vulkan 188 78.3 4.0 Qwen3 8B (Q4_1) ROCm 95 41.2 6.6 Qwen3 8B (Q4_1…
…The way it handles tool integration, file edits, and permissions just feels more polished to me, and I've had better success with local models like Qwen3 Coder Next with Claude Code…
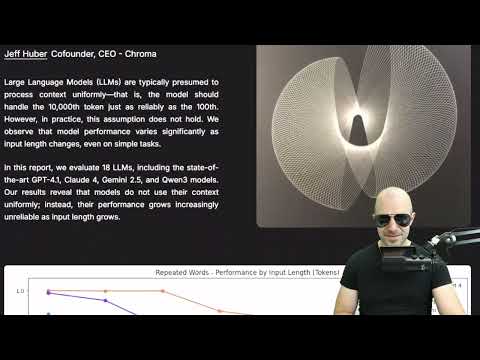
["amd","qwen3","google-gemma"]
Safetensors, llmfan46/Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved: https://huggingface.co/llmfan46/Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved GGUFs, llmfan46/Qwen3.5-35B-A3B-uncensored-here…
Qwen3.6-35B-A3B speculative decoding is net-negative on RTX 3090
We got 207 tok/s with Qwen3.5-27B on an RTX 3090
https://preview.redd.it/42ak5qmus82h1.png?width=1133&format=png&auto=webp&s=744ea3dfc06c83d0c4d8aa128c39b3238b17d7be Qwen 3.7 Max sitting at 5th, pretty much on par with GPT 5.4 (xhigh) and a notch above the just release…
https://w418ufqpha7gzj-80.proxy.runpod.netStarted for myself, but since Im not using it continuously, sharing it:Open Access Qwen3.6-35B-A3B-UD-Q5_K_M with TurboQuant (TheTom/llama-cpp-turboquant) on RTX 3090 (Runpod spo…
…Atom substitution beats matched-norm ablation on 92.4% of n=4{,}851 firings at Qwen3.5-0.8B L9 H4, the 87-atom population test holds at 89.8%, the closed…
…Since my RTX 3080 Ti can drive the bulky Qwen3.6-35B-A3B with relative ease thanks to MoE offloading, I ran it with llama-server and paired it with the Pi…
…In other NVIDIA news, ACE (Avatar Cloud Engine) can now use the open-source Qwen3-8B AI model as an In-Game Inferencing (IGI) SDK plug-in. This simplifies integration within a…
["amd","ryzen","qwen3","windows-11"]
…Related I finally found a local LLM I actually want to use for coding Qwen3-Coder-Next is a great model, and it's even better with Claude Code as a harness…
…Related Qwen3.5-9B tops every AI benchmark right now, but that's not how you should pick a model There's a lot more to a model than just benchmarks. How…