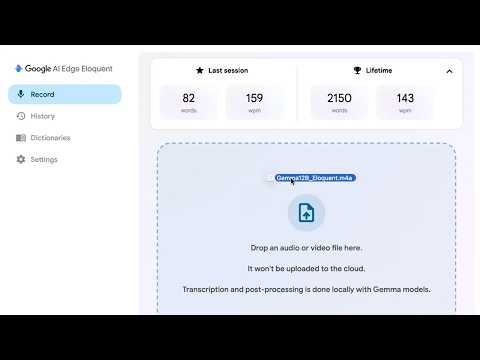
Briefing Findings · Gemma 4 12B is being widely promoted as a
Story-specific findings extracted from this briefing's coverage. Fast Facts in the sidebar holds the canonical reference data (CEO, founded, ticker).
model version Gemma 4 12B
local GPU test Ran Gemma 4 12B on an RTX 3090
hardware constraint Question about running on 16GB hardware
What to Watch
-
Follow up with community tester threads on 16GB hardware performance for Gemma 4 12B.
Level1Techs Forum
What Changed
-
Ran gemma 4 12b on my 3090 yesterday and I think the local model game just changed
Ars Technica
-
Gemma 4 12B on 16GB hardware? Any testers here?
Source-backed brief Show all sources
Broader Google Gemma coverage
· not part of the Gemma 4 12B is being widely promoted as a story