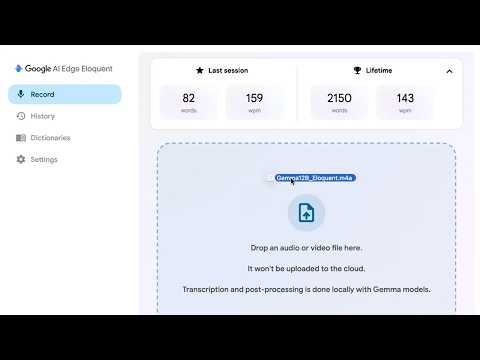
Briefing Findings · Gemma 4’s recent QAT and quantized GGUF work is centered
Story-specific findings extracted from this briefing's coverage. Fast Facts in the sidebar holds the canonical reference data (CEO, founded, ticker).
deployment format GGUF weights released from Unsloth
hardware benchmark AMD 7900 XTX QAT benchmarks reported
use-case caveat Coding/tool calling works with a special chat template
What to Watch
-
Follow Unsloth threads for more Gemma 4 QAT GGUF weight drops.
r/LocalLLaMA
-
Test whether Gemma 4 12B coding/tool calling succeeds when using the special chat template mentioned in the PSA.
What Changed
-
PSA: Gemma 4 12B is NOT completely broken for coding and tool calling, you need a special chat template
Source-backed brief Show all sources
Broader Google Gemma coverage
· not part of the Gemma 4’s recent QAT and quantized GGUF work is centered story