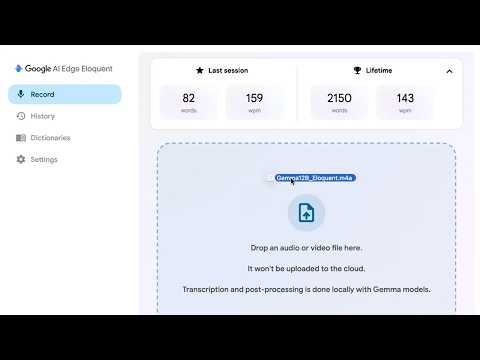
Briefing Findings · Gemma 4 is getting both practical efficiency updates
Story-specific findings extracted from this briefing's coverage. Fast Facts in the sidebar holds the canonical reference data (CEO, founded, ticker).
memory optimization Uses a training trick to slash on-device memory footprint
chat template update Chat Template now includes “preserve thinking”
What to Watch
-
Check the Gemma 4 Chat Template docs/releases for updates related to “preserve thinking.”
r/LocalLLaMA
-
Follow Android Authority coverage for benchmark/usage reports tied to the on-device memory reduction trick.
Android Authority
What Changed
-
Gemma 4 Chat Template now has preserve thinking
Source-backed brief Show all sources
Broader Google Gemma coverage
· not part of the Gemma 4 is getting both practical efficiency updates story