Briefing Findings
Story-specific findings extracted from this briefing's coverage. Fast Facts in the sidebar holds the canonical reference data (CEO, founded, ticker).
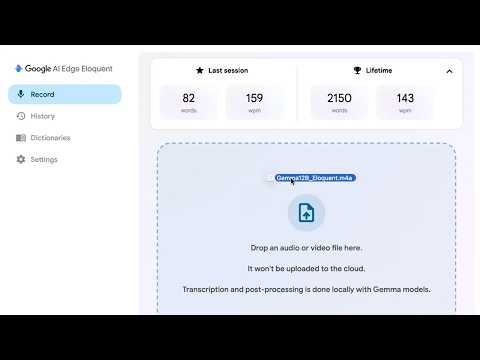
model compared Qwen 3.6 35B-A3B vs Gemma 4 12B
quantization mention Gemma 4 12B suggested with Q8
power claim Gemma 12B reported as <10 watts
inference metric 6.5 pp (1.3 tg noted alongside)
What to Watch
-
Check r/LocalLLaMA threads for follow-ups that report real local benchmarks for Gemma 4 12B (Q8).
r/LocalLLaMA
-
Look for additional community measurements validating the “<10 watts” Gemma 12B claim and the stated throughput figures.
Recent signals
-
Gemma 12b less than 10 watts 6.5pp 1.3tg
-
Qwen 3.6 35B-A3B @ Q4 or Gemma 4 12B @ Q8?
Source-backed brief Show all sources
r/LocalLLaMA