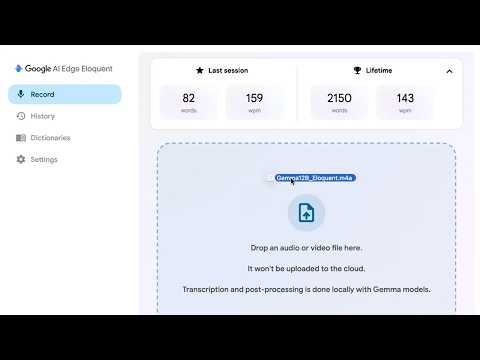
Briefing Findings · Gemma 4 is being positioned as practical to run locally
Story-specific findings extracted from this briefing's coverage. Fast Facts in the sidebar holds the canonical reference data (CEO, founded, ticker).
memory focus Gemma 4 uses a training trick to cut on-device memory footprint
What to Watch
-
Watch for more Gemma 4 variants that further reduce on-device memory, following the “training trick” approach.
Android Authority
What Changed
-
The latest Gemma 4 models use a training trick to slash their on-device memory footprint
Source-backed brief Show all sources
Broader Google Gemma coverage
· not part of the Gemma 4 is being positioned as practical to run locally story