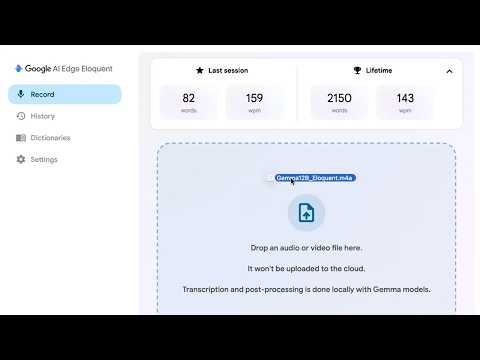
Briefing Findings · Gemma 4 QAT-derived models are improving mobile/laptop
Story-specific findings extracted from this briefing's coverage. Fast Facts in the sidebar holds the canonical reference data (CEO, founded, ticker).
Model focus Gemma 4 12B
What to Watch
-
Look for more Gemma 4 confirmations and follow-up model announcements in the community threads.
HN
What Changed
-
PSA: Gemma 4 12B is NOT completely broken for coding and tool calling, you need a special chat template
r/LocalLLaMA
Source-backed brief Show all sources
Broader Google Gemma coverage
· not part of the Gemma 4 QAT-derived models are improving mobile/laptop story